Stay updated with all the latest news and announcements
The penetration test, or as it is fondly nicknamed, the pentest, has been a security staple for decades.
SOC 2 and ISO 27001 provide a structured approach to managing sensitive information and ensuring data security.
This reflects a broader industry recognition: real-world risk doesn’t occur in silos, and neither should security operations.
Best known for bodyguards and snipers, the U.S. Secret Service has also built an impressive set of advanced cyber capabilities.
RCA is an industry partnership designed to provide retailers with collective defense against cyber threats.
The security flaw was identified in a web application running on US DoD infrastructure.
NYC, New York, August 17, 2025 -(PR)- Silent Breach today announced the official launch of Silent Breach’s Advanced 0-day Lab.
NYC, New York, April 15, 2025 -(EIN Presswire)- Silent Breach announces its participation in GITEX Europe 2025, held this May.
NYC, New York, October 17, 2024 -(EIN Presswire)- Silent Breach announced a major upgrade to its Quantum Armor platform.
NYC, New York, May 31, 2024 -(EIN Presswire)- Silent Breach announces the launch of its Accelerated Cyber Compliance service.
NYC, New York, April 22, 2024 -(EIN Presswire)- Quantum Armor now offers GenAI-powered cybersecurity.
NYC, New York, March 4, 2024 -(EIN Presswire)- TechTimes names Silent Breach the top penetration testing provider for 2024.
NYC, New York, February 11, 2024 -(PR)- Silent Breach today announced the expansion of their penetration testing services.
NYC, New York, January 18, 2023
NYC, New York, September 17, 2022 -(PR)- Silent Breach announced the relocation of its European headquarters to Paris, France.
NYC, New York, August 28, 2022 -(PR)- Silent Breach announced that it has begun offering NFT and blockchain security service.
NYC, New York, May 09, 2021 -(PR)- Silent Breach has expanded their partnership program with a range of competitive incentives.
Silent Breach is pleased to announce that we've been recognized as the top Florida-based Fraud Detection Startup in 2020.
NYC, New York, October 16, 2020 -(PR)- Slovak Telekom.
Silent Breach is honored to announce that we've been recognized as a Top 10 Vulnerability Management Solutions Provider in 2020.
Identity, Control Planes, and the Architecture of Modern Breach
Measuring Resilience Instead of Activity
At population scale, low-sensitivity personal identifiers become high-fidelity attack infrastructure.
This post provides a technical summary of the vulnerability, its exploitation path, and the coordinated disclosure process.
The 2019 Capital One breach exposed personal data associated with more than 106 million individuals stored in Amazon S3.
Year after year, the holiday season produces a consistent and measurable spike in cyber attack activity.
Every CISO faces the unique challenge of justifying a budget whose ROI is predominantly measured by what never happened.
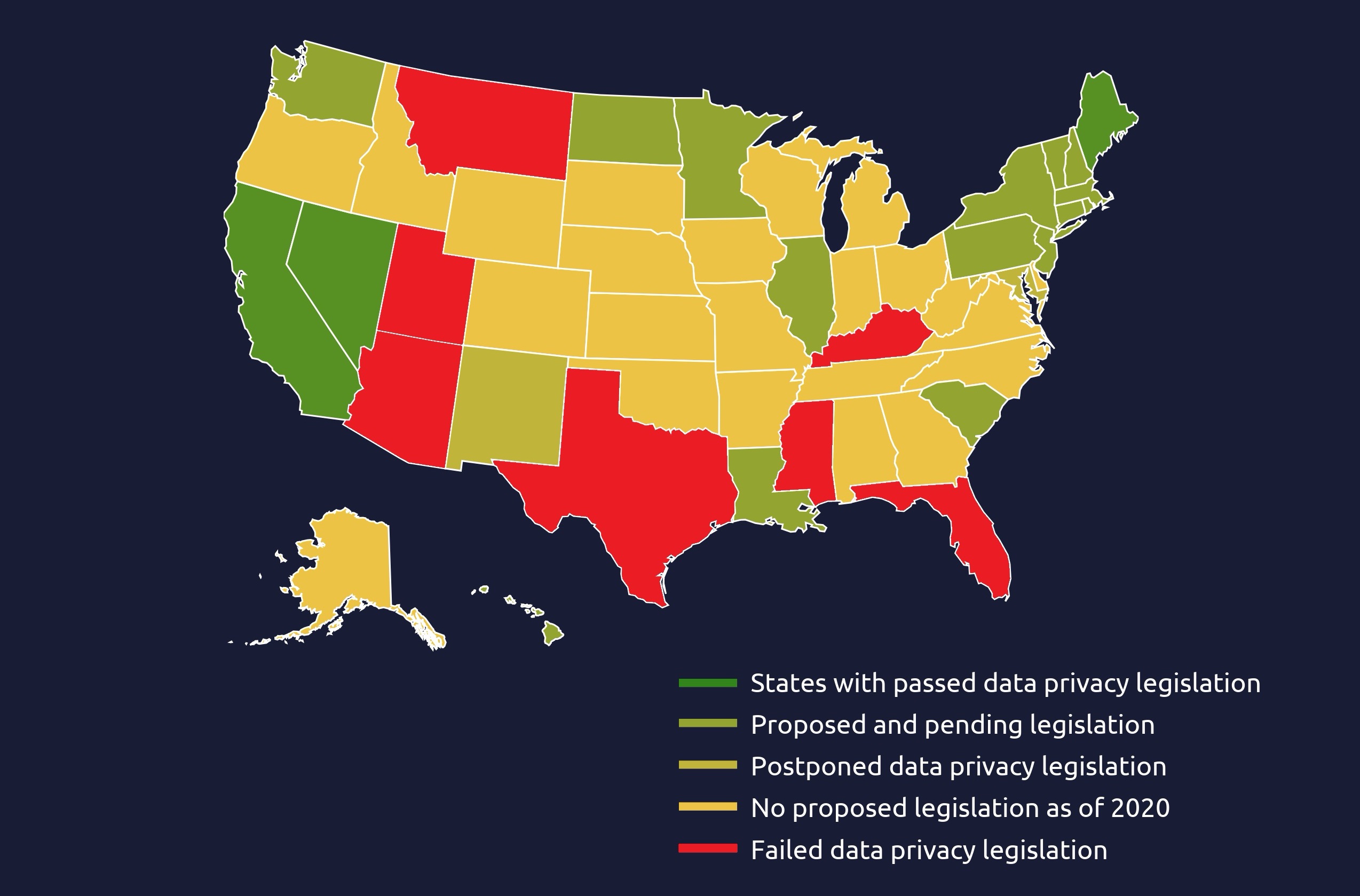
Data privacy protection has become a global trend for organizations, individuals and governments.
FIC 2020 focused on Putting Humans at the Heart of Cybersecurity, making social hacking a key topic across the conference.
Among the more quietly disruptive forces in the cybercrime economy is a relatively new player: the Initial Access Broker (IAB).
Chris Krebs, former CISA Director, was fired Nov 17 after stating the 2020 election was the “most secure in American history.”
Globalization has contributed to the rapid spread of contagions such as COVID-19.
Threat intelligence has come a long way since its humble beginnings as a shared blacklist of malicious IP addresses and URLs.
Ask any CISO about their top priorities, and “compliance” is usually near the top of the list.
Over the past two years, Silent Breach’s 0-Day Lab has seen attackers shift.
Time and again, CISOs tell us that their number one challenge is a lack of organizational buy-in.
China's cybersecurity market has seen rapid growth, fueled by the country's accelerated digital transformation.
A side-by-side breakdown
For small and mid-sized businesses, customer and vendor security demands often arrive faster than internal resources can keep up.
With 95% of the internet hosted on the Deep and Dark Webs, companies can now leverage this data for positive use.
Penetration testing has become an essential part of the modern cybersecurity strategy, and for good reason.
As cyber threats grow more sophisticated, many SMEs turn to Managed Detection & Response to strengthen security posture.
In an era where planes are essentially flying data centers, the need for robust cybersecurity is more pressing than ever.
With rising threats, staying compliant with Singapore’s security laws is both a necessity and a competitive advantage.








%20(1).jpg)














.jpg)











.jpg)





